YOLOv5简介
Ultralytics YOLOv8,这是广受好评的实时对象检测和图像分割模型的最新版本。YOLOv8 基于深度学习和计算机视觉领域的前沿进步而构建,在速度和准确性方面提供无与伦比的性能。其流线型设计使其适用于各种应用程序,并可轻松适应从边缘设备到云 API 的不同硬件平台。
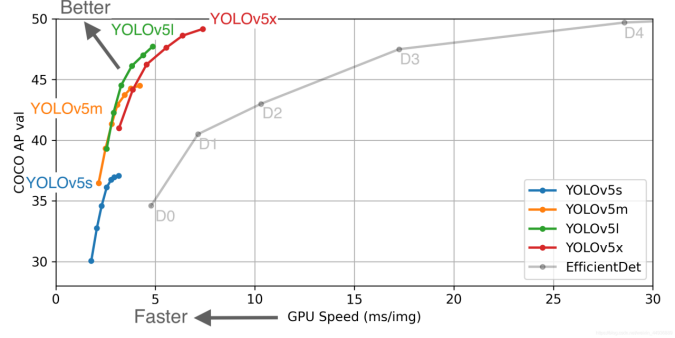
YOLOv5识别算法 s,m,i,x
图二
yolov5有4种识别算法,不同识别算法的特性如上图,这里选择yolov5s,速度最快,但是效果最拉胯
安装YOLOv5(>=python3.8必须)
python3.9的安装可以查看这里
官网地址:https://github.com/ultralytics/ultralytics (github)
https://docs.ultralytics.com/
//更新pip3.9
#pip3.9 install --upgrade pip
1.复制项目
//从github以git包的形式安装ultralytics(YOLOv8)
//Install the ultralytics package from GitHub
git clone https://github.com/ultralytics/yolov5
2.安装python环境 测试笔记中,最低环境需要python3.8.0
安装python3.9后 , 执行:
#pip3.9 install -r requirements.txt
3.下载识别算法(运行测试时会自动下载,但速度慢,改为手动下载) https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt
并将文件放到项目根目录下(上图二)
4.运行识别测试(在根目录内运行)
python3.9 detect.py
-----------------------------------------如果出现以下内容,说明软件正常运行
detect: weights=yolov5s.pt, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 🚀 v7.0-212-g9974d51 Python-3.9.17 torch-2.0.1+cu117 CUDA:0 (Tesla M40 24GB, 22945MiB) //这一句说明你的运行环境
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
image 1/2 /usr/local/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, 29.8ms //这一句说明 识别到4个人,一台巴士
image 2/2 /usr/local/yolov5/data/images/zidane.jpg: 384x640 2 persons, 2 ties, 29.9ms //这一句说明 识别到2个人,2条领带
Speed: 0.4ms pre-process, 29.8ms inference, 3.9ms NMS per image at shape (1, 3, 640, 640) /这一句说明 每个线程用时0.4ms,总用时29.8ms
Results saved to runs/detect/exp2 //这一句说明结果保存在这个目录内
------------------------------------------------------
参数说明
打开文件detect.py
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
--weights 选择哪个识别模型进行识别 (s,m,i,x)
--source 检测目录 '/tmp/01.jpg' \ (screen如果是这个,则对全屏进行识别)
--max-det 最大识别数
//例子
python3.9 detect.py --weights yolov5s.pt --source '/tmp/data/images'
创建自定义训练集的数据
//1.安装图片标记软件 labelImg
#pip3.9 install labelimg
//2.运行labelImg
#/usr/local/python3.9/bin/labelImg
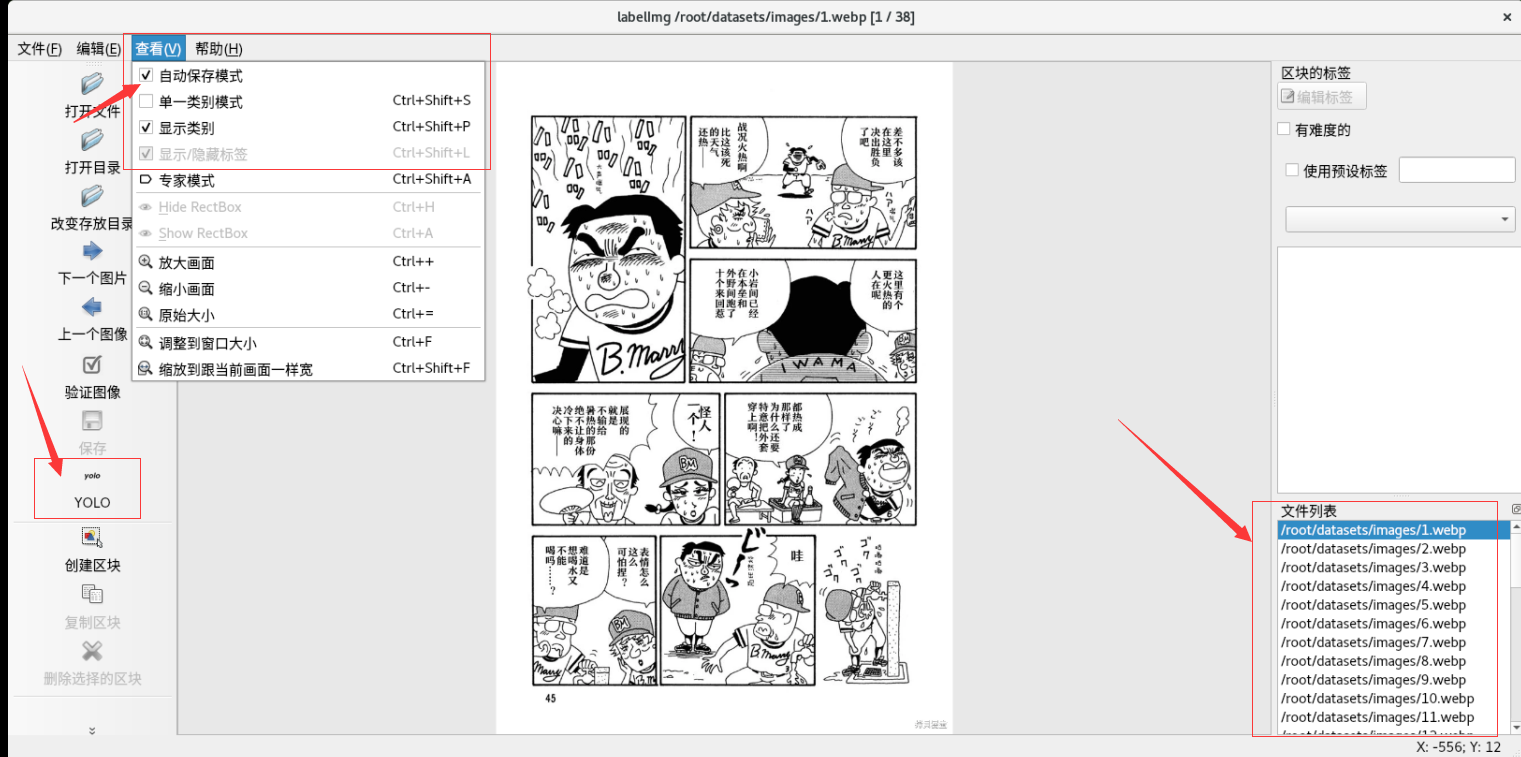
//输出格式选为yolov5的格式,自动保存
//3.选择带有目标的文件夹
//建议的目录结构是 ['dataset'=>['images'(源图),'labels'(存放结果))]]
//4.标记水印(w创建选择区域,a上一张图,d下一张图)
开始训练需要识别的对象(水印)
1.将"练集的数据"放入根目录
/usr/local/yolov5/datasets/copymanga =>['images','labels']
2.复制 /usr/local/yolov5/data 目录下的 coco128.yaml 文件并重命名为 copymanga.yaml
内容改为以下:
----------------------------------
path: ./datasets/copymanga # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: copymanga
----------------------------------
3.修改训练模型中的data路径:
(位置第三个行的位置)
parser.add_argument('--data', type=str, default=ROOT / 'data/copymanga.yaml', help='dataset.yaml path')
4.开始训练
python3.9 train.py
期间可能会出现下载字体文件
Downloading https://ultralytics.com/assets/Arial.ttf to root/.config/Ultralytics/Arial.ttf...
(手动下载到该目录内)
...................
Model summary: 157 layers, 7012822 parameters, 0 gradients, 15.8 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:0
all 10 10 0.00333 1 0.809 0.552
Results saved to runs/train/exp2 结果输出在这个目录内
其中训练好的模型在 runs/train/exp2/weights 内
测试:
python3.9 detect.py --weights runs/train/exp2/weights/best.pt --source /root/1074/2222.webp
python3.9 detect.py --weights 'runs/train/exp3/weights/best.pt' --source '/root/1074/' --save-txt --save-conf --nosave --name '/tmp/1076/res'